Dataclasses in ML Pipelines
Posted on Sun 26 July 2020 in pipelines posts
Tidying up Pipelines with DataClasses¶

Background¶
Tidy code makes everyone's life easier.
The code in an ML project will probably be read many times, so making our workflow easier to understand will be appreciated later by everyone on the team.
During ML projects, we need to access data in a similar manner (throughout our workflow) for training, validating and predicting our model and data. A clear semantic for accessing the data allows for easier code management between projects. Additionally naming conventions are also very useful in order to be able to understand and reuse the code in an optimal manner.
There are some tools that can assist in this cleanliness such as the usage of Pipelines and Dataclasses.
MLEngineer is 10% ML 90% Engineer.
Pipeline¶
Pipeline is a meta object that assists in managing the processes in a ML model. Pipelines can encapsulate separate processes which can later on be combined together.
Forcing a workflow to be implemented within a scikit-learn Pipeline objects can be nuisance at the beginning (especially managing pandas DataFrame within the workflow), but down-the-line it guaranties the quality of the model (no data leakage, modularity etc.). Here is Kevin Markham 4 min. video explaining pipeline advantages.
Dataclass¶
Another useful Python object to save datasets along the pipeline are dataclasses. Before Python 3.7 you may have been using namedtuple, however after Python 3.7 dataclasses were introduced, and are now a great candidate for storing such data objects. Using dataclasses allows for access consistency to the various datasets throughout the ML Pipeline. Additionally you are able to use the auto-complition in your favorite IDE to access all the feilds within the dataclass.
Pipeline¶
Since we are not analysing any dataset, this blog post is an example of an advance pipeline that incorporates non standard pieces (none standard sklearn modules).
Assuming that we have a classification problem and our data has numeric and categorical column types, the pipeline incorporates:
- Preprocess data preparation per column type
- Handle the
categoricalcolumns using the vtreat package - Run a catboost classifier.
We may build our pipeline as follows:
y = df.pop("label")
X = df.copy(True)
num_pipe = Pipeline(
[
("scaler", StanderdScaler()),
("variance", VarianceThreshold()),
]
)
preprocess_pipe = ColumnTransformer(
remainder="passthrough",
transformers=[("num_pipe", num_pipe, X.select_dtypes("number"))],
)
pipe = Pipeline(
[
("preprocess_pipe", preprocess_pipe),
("vtreat", BinomiaOutcomeTreatmentPlan()),
]
)
In this pseudo code our Pipeline has some preprocessing to the numeric columns followed by the processing of the categorical columns with the vtreat package (it will pass-through all the non-categorical and numeric columns).
Note
- Since catboost does not have a transform method we are going to introduce it later on.
- The usage of
vtreatis an example of the possibility to use nonstandard modules within the classifications (assuming they followsklearnparadigms)
So now the time has come to cut up our data...

Test vs. Train vs. Valid¶
A common workflow when developing an ML model is the necessity to split the date into Test/Train/Valid datasets.
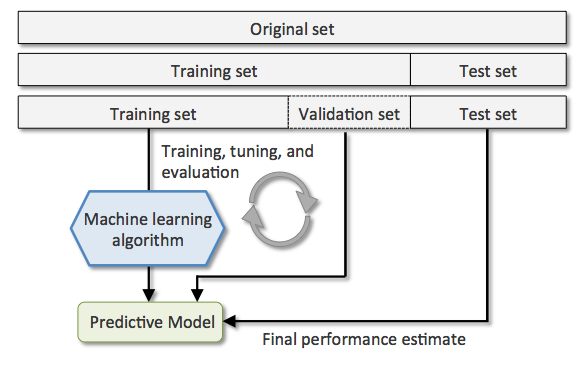
source: Shan-Hung Wu & DataLab, National Tsing Hua University
In a nut shell the difference between the data are:
- Test - put aside - don't look until final model estimation
- Train - dataset to train model
- Valid - dataset to validate model during the training phase (this can be via Cross Validation iteration, GridSearch, etc.)
Each dataset will have similar attributes that we will need to save and access throughout the ML workflow.
In order to prevent confusion lets create a dataclass to save the datasets in a structured manner.
# basic dataclass
import numpy as np
from dataclasses import dataclass
@dataclass
class Split:
X: np.ndarray = None
y: np.array = None
idx: np.array = None
pred_class: np.array = None
pred_proba: np.ndarray = None
kwargs: Dict = None
def __init__(self, name: str):
self.name = name
Now we can create the training and test datasets as follows:
train = Split(name='train')
test = Split(name='test')
Each dataclass will have the following fields:
X- a numpy ndarray storing all the featuresy- a numpy array storing the labeling classificationidx- the index for storing the original indexes useful for referencing at the end of the pipe linepred_class- a numpy array storing the predicted classificationpred_proba- a numpy ndarray for storing the probabilities of the classifications
Additionally we will store a name for the dataclass (in the init function) to easily referencing it along the pipeline.
Splitting In Action¶
There are several methods that can be used to split the datasets. When data are imbalanced it is important to split the data with a stratified method. In our case, we chose to use StratifiedShuffleSplit however, in contrast to the simple train-test split which returns the datasets themselves, the StratifiedShuffleSplit returns only the indices for each group, thus we will need a helper function to get the dataset themselves (our helper function is nice and minimal for the usage of our dataclasses).
def get_split_from_idx(X, y, split1: Split, split2: Split):
split1.X, split2.X = X.iloc[split1.idx], X.iloc[split2.idx]
split1.y, split2.y = y.iloc[split1.idx], y.iloc[split2.idx]
return split1, split2
for fold_name, (train.idx, test.idx) in enumerate(
StratifiedSplitValid(X, y, n_split=5, train_size=0.8)
):
train, test = get_split_from_idx(X, y, train, test) # a helper function
Pipeline in action¶
Now we can run the first part of our Pipeline
_train_X = pipe.fit_transform(train.X)
Once we have fit_transform our data (allowing for vtreat magic to work), we can introduce the catboost classifier into our Pipeline.
catboost_clf = CatBoostClassifier()
train_vlaid = Split(name="train_vlaid")
vlaid = Split(name="vlaid")
for fold_name, (train_vlaid.idx, vlaid.idx) in enumerate(
StratifiedSplitValid(_train_X, train.y, n_split=10, train_size=0.9)
):
train_vlaid, vlaid = get_split_from_idx(_train_X, train.y, train_vlaid, vlaid)
pipe.steps.append(("catboost_clf", catboost_clf))
pipe.fit(
train_size.X,
train_vlaid.y,
catboost_clf__eval_set=[(valid.X, valid.y)],
)
Notice the two following points:
- Using
pipe.steps.appendwe are able to introduce steps into the pipeline that could not be initially part of the workflow. - Adding parameters into the steps within the pipeline requires the use of double dunder for nested paramters.
Finally we can get some results
test.pred_class = pipe.(test.X)
test.pred_proba = pipe.pred_proba(test.X)[:,1]
Now when we analyse our model we can generate our metrics (e.g. confusion_matrix) by easily referencing to the relevant dataset as follows:
from sklearn.metrics import confusion_matrix
conf_matrix_test = confusion_matrix(y_true=test.y, y_pred=test.pred_class )
Conclusion¶
This blog post outlins the advantages for using Pipelines and Dataclasses.
Working with the Dataclasses is really a no-brainer since it is very simple and can easily be incorporated into any code base. Pipelines require more effort while integrating them into the code, but the benefits are substantial and well worth it.
I hope the example illustrated the potential for such usage and will inspire and encourage you to try it out.